
Mitchell Hashimoto
Journaux liées à cette note :
Comment "harness" s'est répandu en IA et pourquoi ce terme a été choisi
Le week-end dernier, j'ai commencé à chercher d'où venait le terme harness et pourquoi il a été choisi pour désigner ce concept dans les AI agents comme OpenCode ou Claude Code.
Cette note est le résultat de ce travail de recherche, basé sur des échanges avec Sonnet 4.6, des lectures de commentaires Hacker News et divers articles sur le sujet.
En novembre 2025, Anthropic a publié l'article « Effective Harnesses for Long-Running Agents », qui utilise explicitement « agent harness » dans le sens moderne.
Le terme « harness engineering » semble avoir été popularisé par Mitchell Hashimoto dans la section 5 de son billet publié le 5 février 2026. Il y décrit une pratique qu'il a développée au fil de son usage des agents IA :
Je ne sais pas s'il existe un terme largement accepté par l'industrie pour cela, mais j'en suis venu à appeler cela « harness engineering ». C'est l'idée que chaque fois qu'on constate qu'un agent commet une erreur, on prend le temps de concevoir une solution pour que l'agent ne commette plus jamais cette erreur. Je n'ai pas besoin d'inventer de nouveaux termes ici ; s'il en existe un autre, je m'y joindrai.
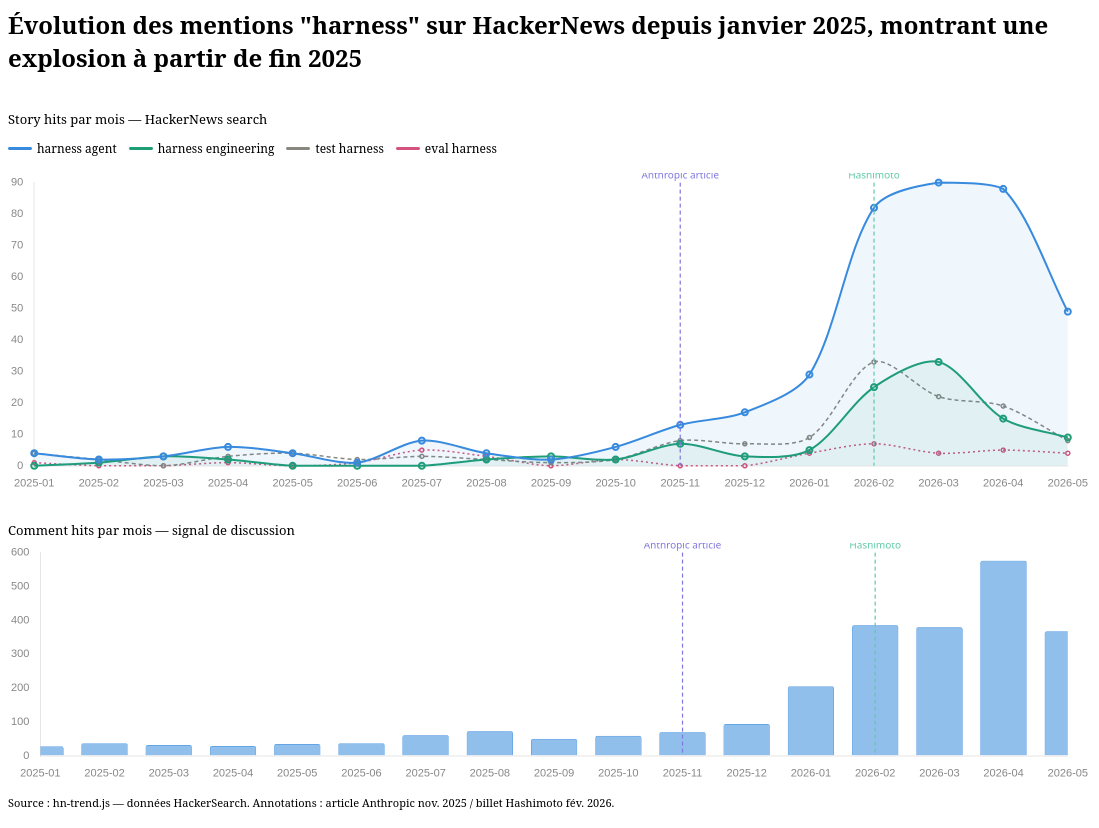 Données extraites avec hackernews-trends-poc.
Données extraites avec hackernews-trends-poc.
Jusqu'à présent, je pensais à tort que l'analogie du harnais correspondait simplement à l'équipement qu'on pose sur un cheval, sans saisir la pertinence de ce terme, par manque de culture de cette langue. En anglais, on trouve les expressions « harness the sun » ou « harness the wind ». Voici la définition du verbe harness :
Verb
harness (third-person singular simple present harnesses, present participle harnessing, simple past and past participle harnessed)
- (transitive) To place a harness on something; to tie up or restrain. Synonym: tackle
« They harnessed the horse to the post. »- (transitive) To capture, control or put to use. « Imagine what might happen if it were possible to harness solar energy fully. »
- (transitive) To equip with armour.
Le terme français qui me semble le plus proche du verbe harness serait « canaliser » ou « dompter ».
Le terme harness désigne donc l'action de canaliser et d'orienter la puissance d'un LLM vers un objectif souhaité.
Avant l'usage du terme harness dans le domaine de l'AI — que ce soit pour agent harness, harness engineering ou LM Evaluation Harness — j'ai découvert en travaillant sur cette note qu'il était déjà utilisé en software engineering, principalement dans l'expression test harness. Il me semble que c'était d'ailleurs l'usage principal du mot dans notre domaine, bien avant qu'il ne soit repris pour les agents IA.
Les concepts que je pense avoir identifiés et que je retiens
- Le harness est un artefact à installer et configurer dans OpenCode. Il est composé de :
- Le harness engineering est le processus humain d'amélioration itérative du harness. Quand l'utilisateur observe une erreur de l'agent, il modifie ou ajoute des fichiers
AGENTS.md,SKILLS.md, des outils MCP ou des configurations pour qu'elle ne se reproduise plus. Ce terme désigne le processus, par opposition au harness qui est l'artefact. - Agent-eval-harness est un outil externe au harness permettant de lancer des sortes de tests unitaires. Il est utilisé pendant les phases de harness engineering pour valider les modifications de façon contrôlée et reproductible.
Cette note ne traite pas de la boucle agent en elle-même — j'ai documenté ce concept séparément ici :
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise.
Le concept de harness vient encadrer cette boucle pour la configurer et la contraindre, mais il ne la définit pas. Comprendre la boucle aide à saisir ce qu'orchestre le harness.
Extrait d'un article de Sebastian Raschka :
Pour clarifier les concepts :
- LLM : le modèle brut de prédiction du prochain token
- Modèle de raisonnement : un LLM optimisé pour produire des traces de raisonnement intermédiaires et se vérifier davantage
- Agent : une boucle qui combine un modèle avec des outils, de la mémoire et des retours d'environnement
- Agent harness : le scaffold logiciel autour d'un agent qui gère le contexte, l'utilisation des outils, les prompts, l'état et le flux de contrôle
- Coding harness : un cas particulier d'agent harness ; un harness spécifique au génie logiciel qui gère le contexte du code, les outils, l'exécution et les retours itératifs
Quelques articles que j'ai lus avec attention :
- Effective harnesses for long-running agents — Anthropic, nov. 2025
- My AI Adoption Journey — Mitchell Hashimoto, fév. 2026
- Components of a Coding Agent — Sebastian Raschka, avr. 2026
En explorant le sujet de harness, je constate que, comme beaucoup de concepts, sa définition peut varier selon les sources et les communautés. Par exemple, l'article Components of a Coding Agent de Sebastian Raschka semble en proposer une définition plus large que Mitchell Hashimoto.
Pour le moment, je souhaite adopter la version de Mitchell Hashimoto, que j'arrive mieux à appréhender et dont je parviens mieux à délimiter le périmètre : un dispositif qui canalise la fougue du LLM, comme le harnais canalise le cheval sauvage.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Journal du mercredi 05 mars 2025 à 16:02
J'ai lu le billet de Mitchell Hashimoto « As code ».
Voir aussi configuration as code.
Journal du mercredi 02 octobre 2024 à 09:34
#JaiLu l'article Pledging $300,000 to the Zig Software Foundation de Mitchell Hashimoto. Très bonne nouvelle pour Zig 🙂.
Deux threads Hacker News à ce sujet : https://news.ycombinator.com/item?id=41712239 et https://news.ycombinator.com/item?id=41711601.